


I’m sure you’ve found yourself in this situation: you want to edit something, but in multiple places, and at the same time. You’re busy; you don’t want to repeat yourself, and this is the twenty-first century and we do have the technology to do this!
I’ve talked about this too-common problem before: multi-occurrence editing with iedit is one such package; the ubiquitous, and excellent, multiple cursors package is another common one.
Editing multiple occurrences either simultaneously or in sequence is not a new invention. Good, old C-M-% (M-x query-replace-regexp) is sometimes the right choice if you can capture your matches and desired replacements with a regular expression. If that approach does not work, then why not reach out and touch a bunch of stuff with multiple cursors? If you dislike multiple cursors, you can confect a fancy keyboard macro to do the work instead (sadly, the fans of keyboard macros are far too occupied to join us right now, as they are busy trying to re-record or edit the macro steps so it works properly.)
No matter the tool, you’re still limited by your ability to collect the right places to edit. These tools can in principle drop cursors anywhere you want them to, but the problem is that outside of a handful of obvious things (same column offset on each line; each word or symbol matching something; the cadence of text using forward-word; etc.) you must compel these tools to place the cursors where you want them to, and that is often manual, verging on tedious, and not always possible.
That’s where tree-sitter and its concrete syntax tree of your source code enter the frame.
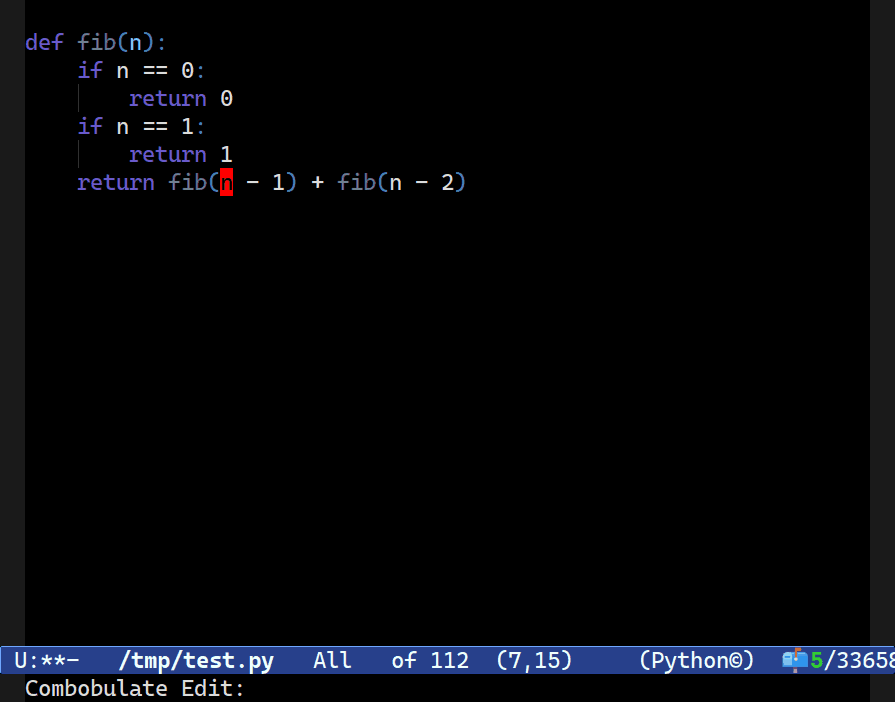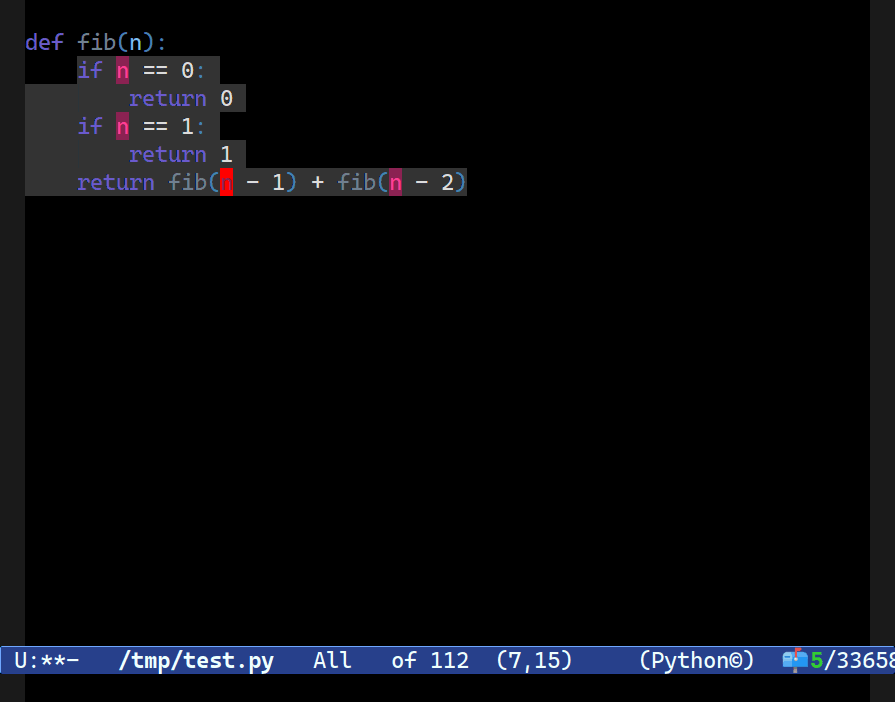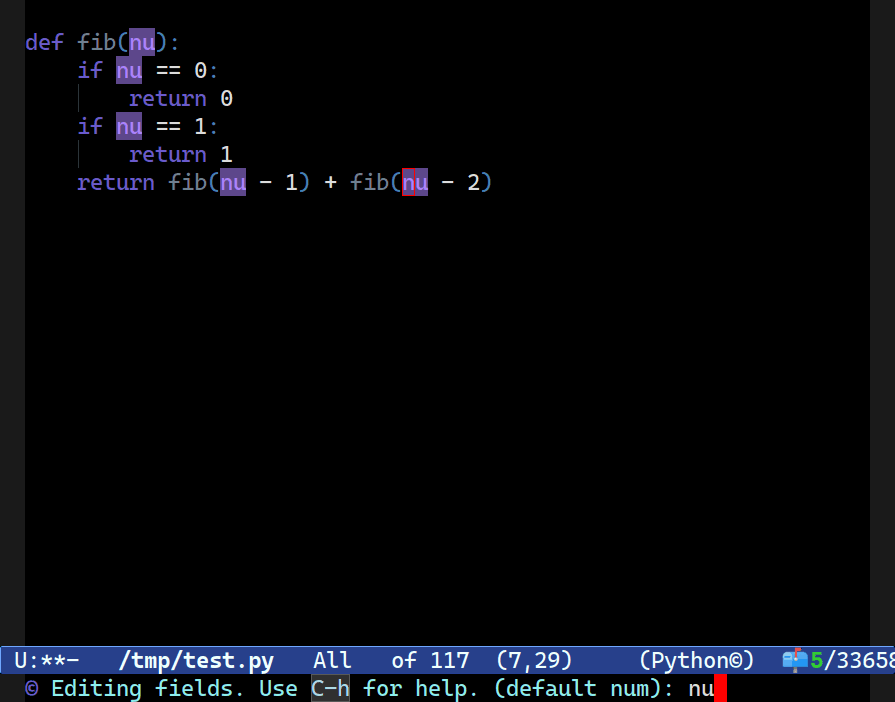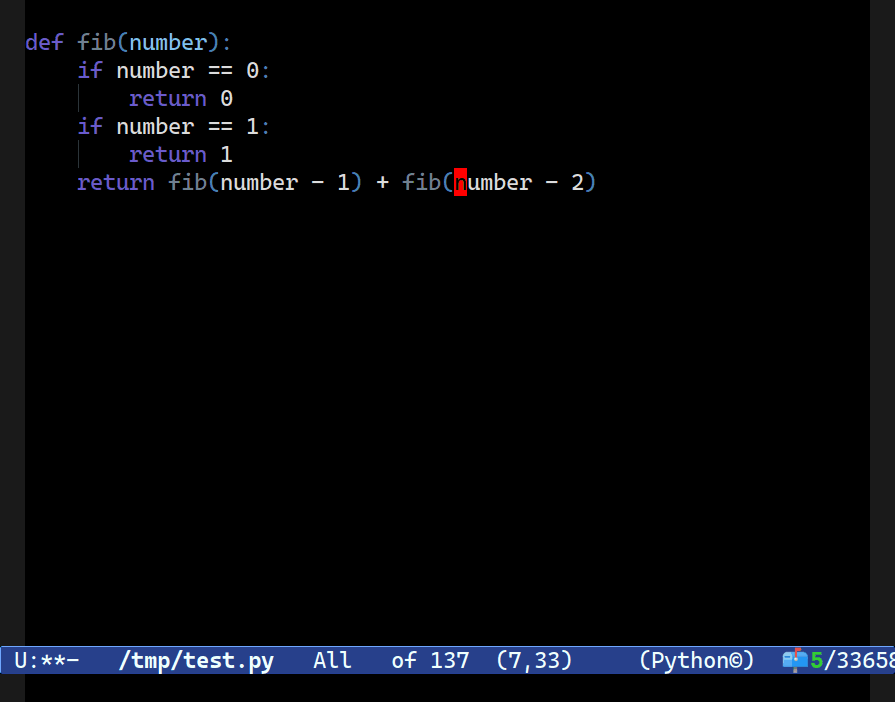
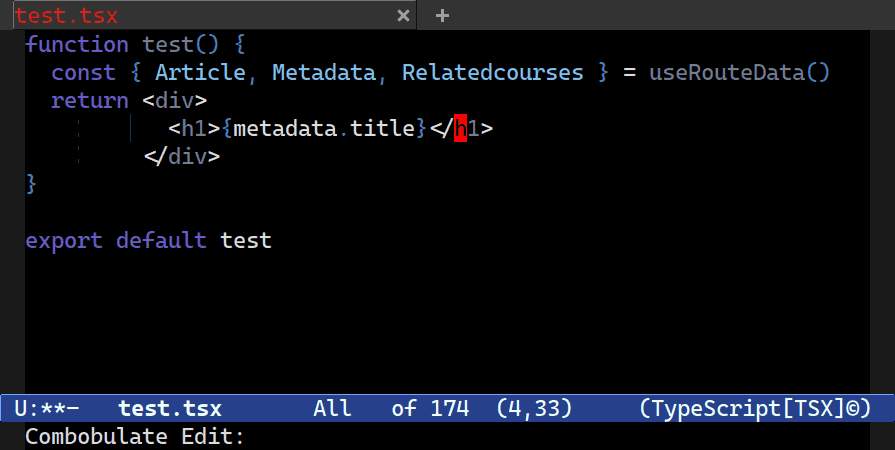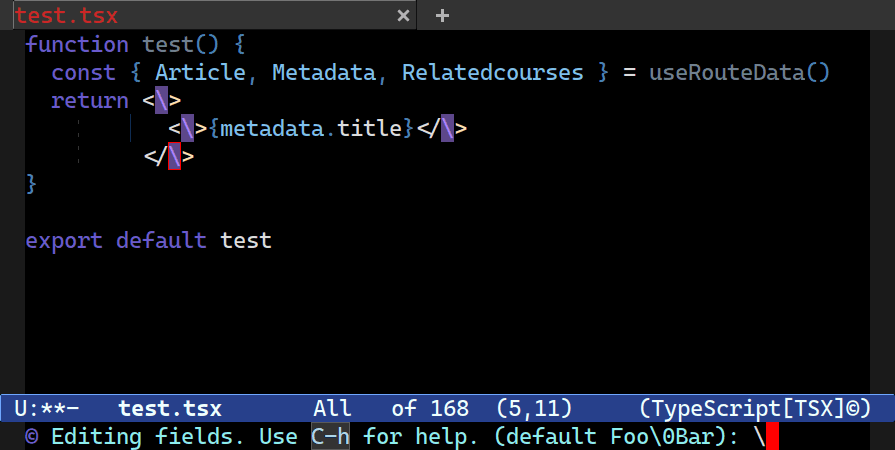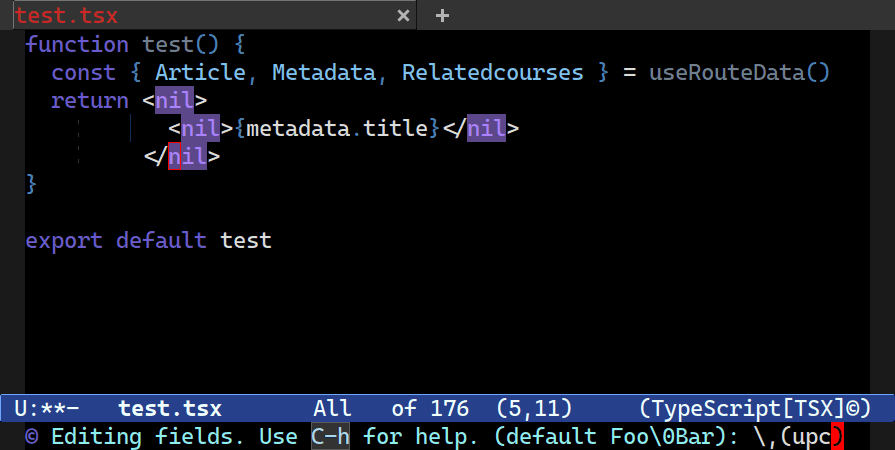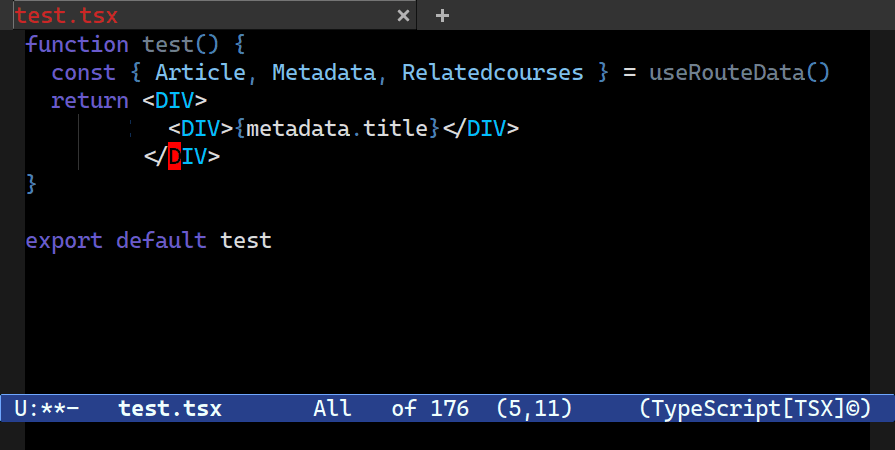
C-c o t x, to pick the node at point’s text (here named n) and then I progressively expand the search scope for similarly-named nodes before renaming them all using Combobulate’s new field editor. More on that below.In Combobulate, my easy-to-use package that adds navigation and editing to tree-sitter-supported languages, that was one of the first things I wanted to support way back in the day when I first built the prototype version.
You see, with a concrete syntax tree, it’s trivial to throw down a cursor at every member of an array, for example, but precisely so there’s no worry about accidentally picking things that may look like an array element – something that is bound to happen if you were to try and do this using more naive means, like with imperative code or regular expressions – but isn’t. If you’ve ever over- or under-selected stuff with a keyboard macro or the likes of multiple cursors, then you know what I mean!
That’s why I want to talk about Combobulate’s cursor editing functionality; some of the unexpected challenges around building it; and a new method of doing cursor editing without relying on third-party tools like multiple cursors.
Picking the Right Things With a Query
Before I get into all the ways that Combobulate can help you edit with multiple cursors, I want to first outline some of the challenges around picking things the things you want to edit. For all the talk I did around how much better a concrete syntax tree is – and it is infinitely better – there are snags.
Combobulate, when I first set out to write it, had to work uniformly across a wide range of languages that I used professionally: Python, bash, Typescript + TSX, HTML, CSS, etc.
If you’re at all familiar with tree-sitter, you probably know that you can build s-expression-alike queries, and that is one of the main ways of interfacing with the tree it makes.
Here’s one such made-up example, and it (or something akin to it) is a common thing to want to edit. Given the following query and a starting node, you can tag nodes in the query with @mytag to indicate that you want tree-sitter to return said nodes, provided there are matches of course:
(object
(pair
key: (_) @match))How do you edit the keys in an object/dictionary without tree-sitter? It’s easy enough with traditional tools if the keys line up in your buffer with surgical precision. But what if they don’t? Perhaps they’re disordered and not formatted well, so you can’t just go to the next line with the same offset, or hope forward-sexp and friends can get you there. Tree-sitter makes it a cinch to pluck them anyway.
The example above works by tagging any node that matches (_) (we could limit it to (string) also, for example, to collect only string keys) using the key: field, which is inside a pair, which is also inside an object. Here @match is a made-up tag, so we’d have to do some leg work to feed it to multiple cursors, of course, but that is not terribly hard.
That’s also how TS-based syntax highlighting works: you tag stuff with the name of the face (such as @font-lock-string-face) you want, and Emacs’s font lock engine colors the matches according to the list of queries you have given it. Same query engine, distinct use cases.
It’s a defining feature of tree-sitter. I doubt it would have seen much adoption without it, to be honest. Combobulate has an excellent interactive query builder complete with code completion and syntax highlighting, so you can try it out yourself. (Spoiler alert: you can tell Combobulate to edit stuff based on a query. Give it a try!)
For all the marvelous benefits of tree-sitter’s query matching engine, it has a humongous, frustrating black mark against it.
When Queries Fail
Can you guess what it is?
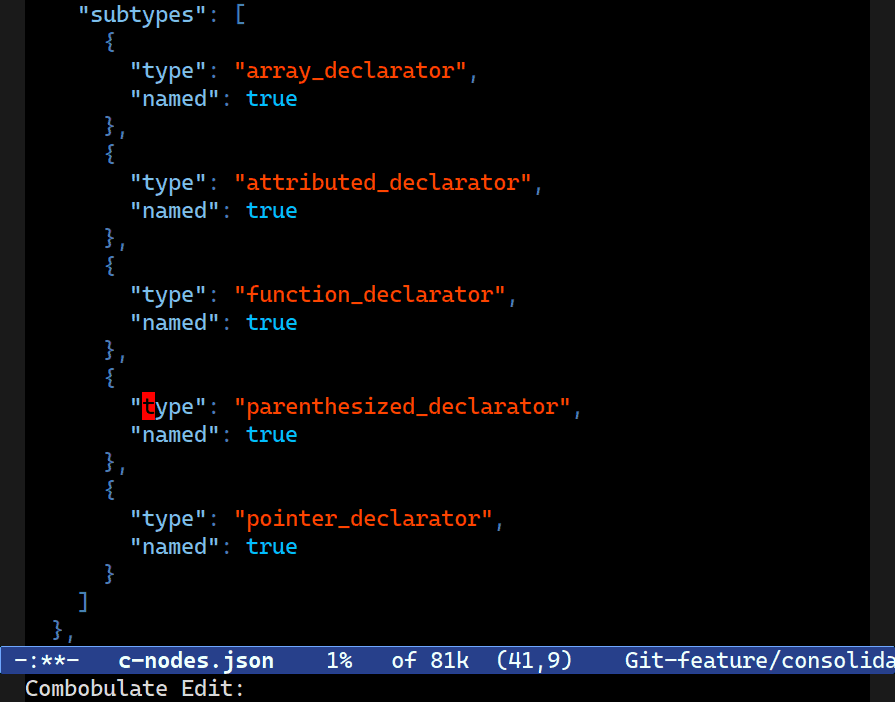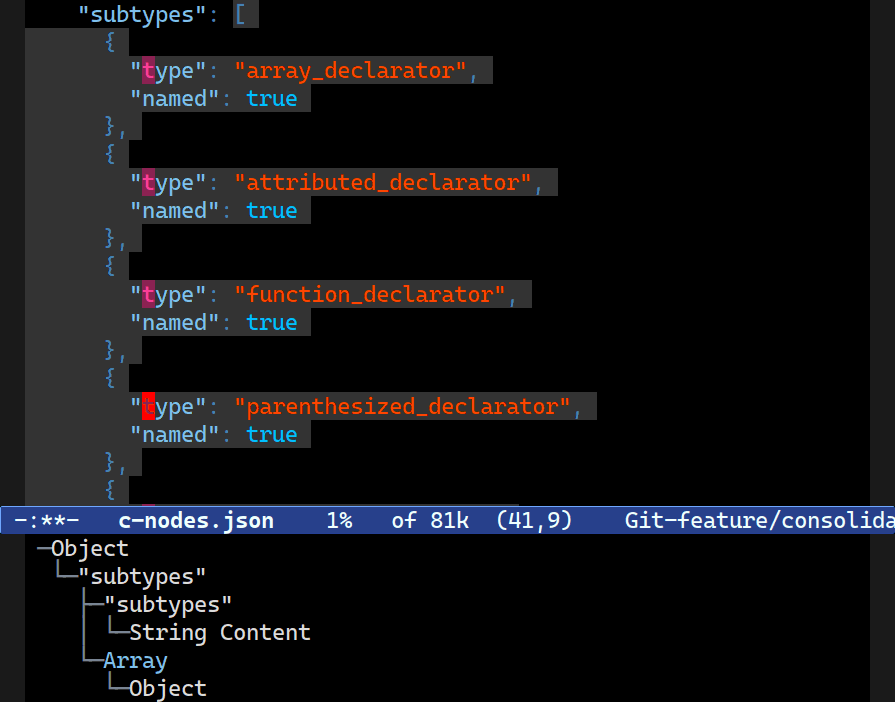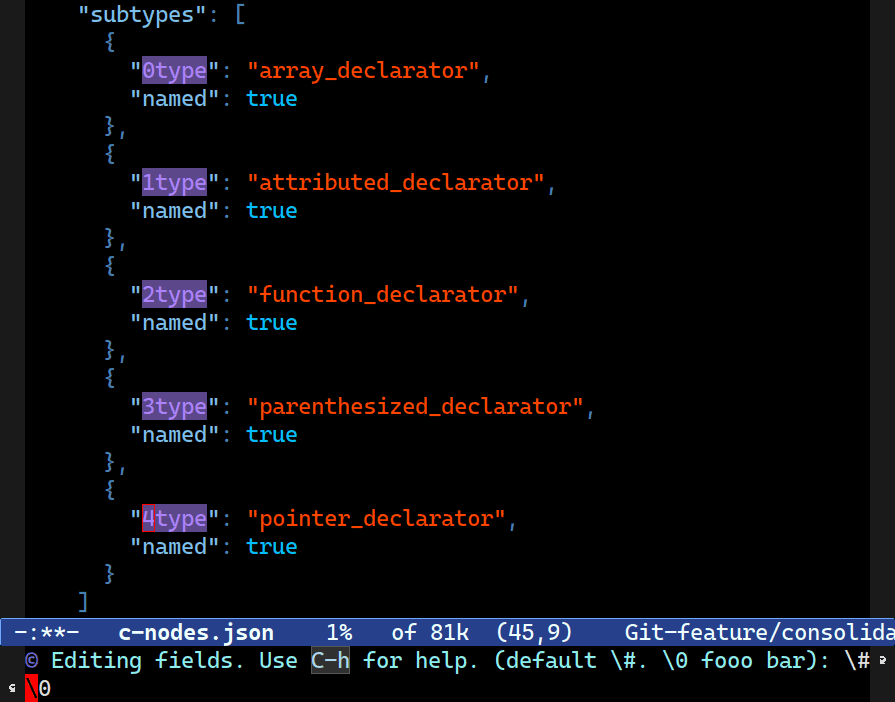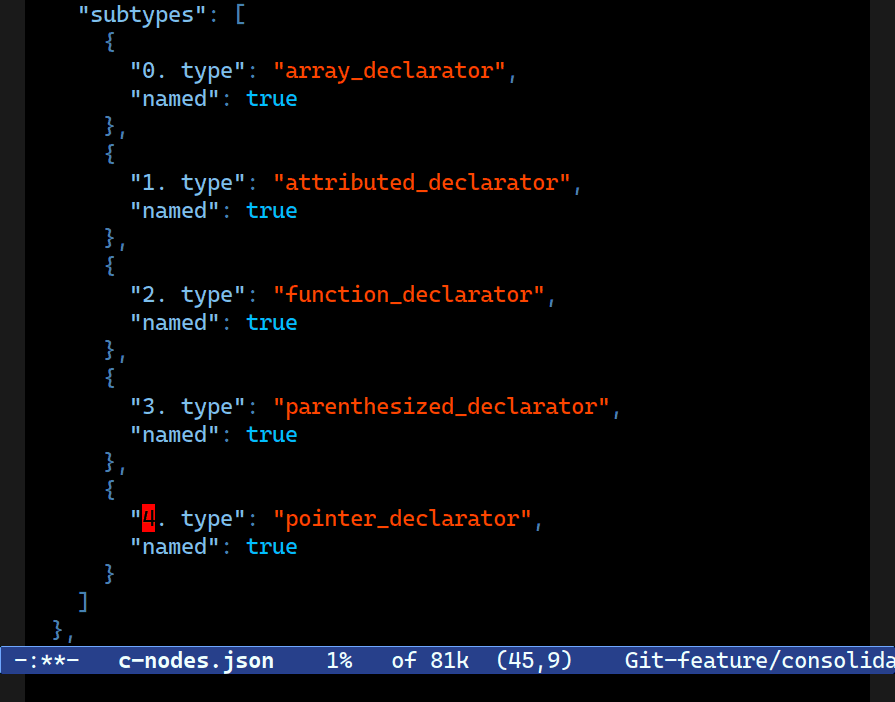
Let me show you a picture — it’ll give it away:
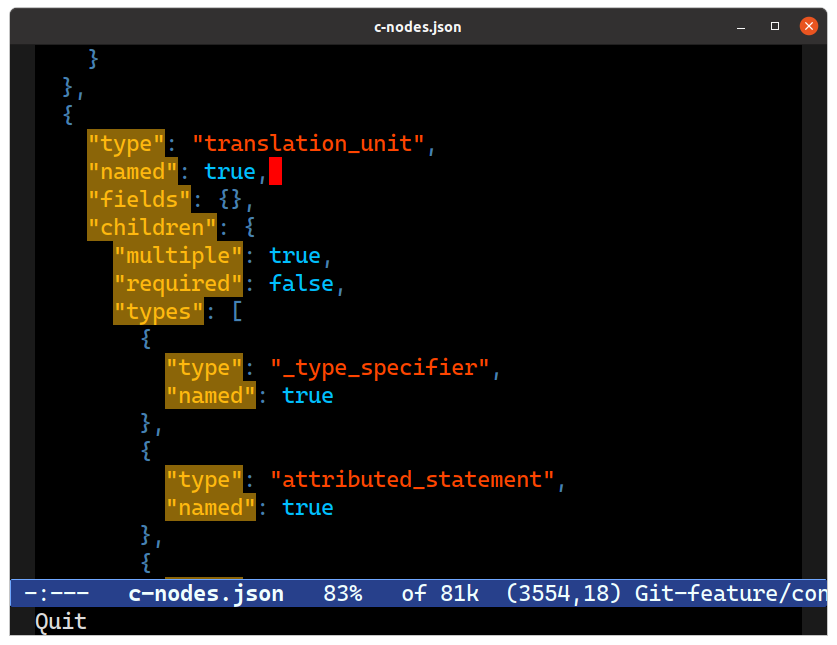
C-c o B q) is highlighting all the matches using the aforementioned query. Observe how it matches all nested keys also.It’s recursive. That is a useful property for highlighters or general-purpose “sally forth and find me all matches” needs, which is admittedly a large tract of why you’d use the query engine.
But it is not so useful if you want to edit just one level of keys in an object, or – as I discovered when I started using it in anger – the start and end elements in HTML or TSX. Any sort of self-similar nodes (nested anything, like HTML tags) are immediately snared by this feature.
You know, I just wanted to add basic multi-editing to early versions of Combobulate: simultaneously renaming matching HTML tags. That sort of thing. The query system seemed like the perfect abstraction. I could literally describe what I wanted to edit.
Womp, womp. Except I couldn’t. Not with the query engine, mind — not without attempting error-prone post-processing to weed out false positives, somehow. But that, in my mind, ran against the philosophy of capturing the requirements in a declarative query, and that Combobulate should not special-case code for each language it supports. (That is an adamantine rule that still stands.)
The workaround, if you can call it that, is to anchor the query to the root node – that “disables”, by way of exclusively matching all of a node’s parents, for there is just one root node in a tree – the recursive check. Thus, given a node in a tree, it is possible to construct a query that matches just that node, though you would have to describe the entire relationship of the tree, from leaf-to-trunk, and all its siblings along the way.
So to match an object, without recursion gumming things up, in Javascript, nested in a function somewhere, would look like this, but far more complex in real life:
(program
(some_function
(something_else
(...
(object ...)))))Alas, that is not exactly a solution worth talking about.
So how to fix it, then?
The Query “Fix”
So I “fixed” it by reimplementing a large proportion of the tree-sitter query engine in elisp. That was a complex project that took quite a long time to get “right”, for some definition of right, when I wrote it some years ago now. The implementation surely still has bugs. I know it does, because tree-sitter’s official query builder still has a steady stream of bug fixes getting merged. And if that is still buggy, then so is mine!
It’s also kinda slow, so it’s never going to help you font lock your code! I also decided to take a few of the lesser-used features of Emacs core that are perfect for this type of Computer Science problem for a spin: generator functions using iter-defun and friends. Generators are implemented entirely using Lisp macros, which is kind of neat. Writing all that Lisp macrology must’ve been a fun hobby project to build and design, for sure, but it’s not so fun to use: it feels quite slow and cannot be debugged easily. And good luck understanding the macroexpanded code it makes. Yikes.
So. Combobulate’s query engine is not designed to replace tree-sitters’. It’s now a complement to the little declarative mini-language in Combobulate that I settled on so I could support intuitive, structured navigation (called the procedures).
That means it’s possible to ask Combobulate to find stuff the normal way, and then use its (or TS’) query language for finesse:
(procedures-sequence
'((:activation-nodes
((:nodes ("tag_name") :position any :has-ancestor ("element")))
:selector (:choose parent :match-query
(:query
(_ (start_tag (tag_name) @match)
(end_tag (tag_name) @match))
:engine combobulate)))))For example, you can use C-c o t c (cursor edit by sequence) to edit matching HTML tags, and when you do so, this is the DSL declaration it “runs” to determine what to do. (If you’re inside a tag_name and it has an ancestor element then trigger the :selector)
The underlying query (see :query), such as it is, works fine in TS’s query engine also, but with the side-effect of being recursive.
I wrote the query engine back when I thought queries would play a much larger role in Combobulate. Back then, I naively assumed (as you do) that with the bountiful choices made available by a concrete syntax tree, all I had to do was write The Right Query and I could avoid a lot of imperative hand-wringing.
As it turns out, the query engines (plural) are useless for most things related to structured navigation and editing. So despite the theoretical utility of the query engines, in reality I am slowly replacing most of the queries – the few that still remain today – with the DSL.
The DSL is ironically better at picking things, despite its imperative-yet-declarative nature than an all-singing, all-dancing but weirdly limiting set of query engines.
One example of where the DSL wins is sibling navigation, a topic I have covered at length before. Before I came up with the DSL, I’d started the arduous task of using building queries to pick all the keys in a dictionary; the arguments in a function definition; and so on, and so forth. Far too tedious as the query language is too limiting.
Who knew?
So, today, the query engines remain useful mostly for ad hoc highlighting; bulk editing, yes, still; and deft selection of nodes when the mini-DSL fails to do the job.
You might wonder why I haven’t just extended my query language to suit my every need.
The answer is that I feel that it is not really feasible to express these ideas in a language that – if we are to hew somewhat close to the original intent of the tree-sitter query language, and if we do not do that, then my DSL is already such a language! – is boxed in by its desire to be (as it should be!) a pattern matching language with a bunch of deterministic finite automata tacked on to solve the unenviable problem of having to support optional matches, quantifiers, negation, and so on.
The DSL meanwhile relies on the idea of doing simple node type matching and then ascending or descending the tree to match other things based on simple set-theoretic filters and a handful of hardcoded instructions, such as “give me all the things that can go in an if statement except for this or that and then give me all siblings that match something else entirely”.
So that is a brief summary of how the query engine looks like a panacea, but is ultimately not a great fit for most multi-cursor editing tasks, and indeed most precision editing and movement tasks, as you’d have to fight it and write a lot of imperative code anyway.
Right. Let’s talk about some fun things instead.
Cursor Editing
Combobulate’s had cursor editing for a long time. I recently rewrote the system to get rid of what was formerly known as cluster editing: basically the stuff you just read about. Like editing matching HTML tags.
That feature is now called sequence editing, which uses the procedure system to edit any sequence Combobulate knows about, such as the oft-repeated HTML tags.
My impetus for doing this is that the bulk of the cluster editors I’d written were a parallel way of doing sibling editing before I had proper, reliable sibling navigation.
Sibling navigation is one of the most important keystone features in Combobulate as it is such a powerful catalyst for nearly all other editing and movement features in Combobulate, surprising as that may sound!
Case in point: keys in a dictionary; elements in an array; function arguments. They are all siblings. They should be editable as siblings. And now they are.
The C-c o t s command invokes the sibling editor. It works in any place where regular C-M-n and C-M-p sibling navigation works, as it uses the same code base.
If I didn’t use the sibling system, I would’ve had to build a custom cluster query to mark the nodes instead. Tedium squared.
But that’s all gone now. Except…
Clusters & Sequences
The tag names in HTML tags (the div in <div>) are not siblings:
(element
(start_tag (tag_name))
(end_tag (tag_name)))Start and end tag are siblings, but we do not sibling navigate by start or end tag, but element. (There are good reasons for this.) So a call to C-c o t s with point at <div> would instead edit all sibling elements and not the two tag names. That, and the point would be in the wrong place: it should be here: -!-div. Not to the left of < in <div> and </div>. You can’t even C-f once to correct for it, as closing tags terminate with </ and not <, so you’d be off by one!
That’s why we still need some form of “clustered editing”. Though in this case I scried an opportunity to improve navigation as well as retaining tag editing.
New to the latest version of Combobulate is sequence navigation, bound to M-n and M-p. Most nodes lack a sequent; it is not a general purpose movement command, as it only applies in situations where nodes are sequences but not strictly speaking siblings.
Put point inside a <tag> and you can use M-n/p to cycle between the start and end tag. That is super helpful if you work with SGML-alike languages. Use C-c o t c to sequence edit them.
Now you have useful navigation and editing capabilities for places where things are not-quite-adjacent (like JSX and HTML). (If you can think of other cases, do raise a Github issue.)
Ironically, this is a fine use case for the DSL and Combobulate’s query engine to ensure I drill down and pluck the tag names from the start and end tags.
Sequence Scanning
16+ years ago I wrote an awful lot of Borland Delphi for a living. I won’t get into how amazing the UI development experience was except to say that where that was the zenith of productivity, its garbage-tier code editor was surely the nadir. It didn’t even indent your code for you. Bah.
It was a terrible editing experience, except for one little feature I loved in a third-party plugin: keyword scanning. If you pressed M-p or M-n on any identifier in the editor, it’d jump to it, but without the obsequiously stupid “Find Dialog” getting in your way to “help you find what you want”.
I loved it so much it was one of the first things I wrote in Emacs Lisp, and talked about much later here. I called it Smart Scan: Jump between symbols in a buffer.
I still use it. But it annoyed me that I didn’t have a similar feature in Combobulate so others can benefit from its utility, and that the two keys the new sequence key bindings are now bound to conflict with smart scan.
So I merged the features. If your point is in one of the few supported sequences, Combobulate will abide and only move between them. Try to move outside the “range” of valid options, and you’re shown an error: tap the key again without hesitation, and it switches to free-form scanning for that keyword anywhere in the buffer and “outside” the reign of tree-sitter. (It’s effectively akin to regexp searching for \<foo\>.)
Use it anywhere else, and it launches into a freeform search mode for the symbol at point without first raising an error. The end result is you can safely navigate sequences and not worry about getting pulled away from what you’re looking for, while still having the freedom to do search out of bounds, so to speak, if you tap the key again.
Bulk Editing with Combobulate
There’s a handful of bulk editing commands that come with Combobulate.
| Key Bindings | Description |
C-c o t t |
Edit by node type DWIM |
C-c o t x |
Edit by node text DWIM |
C-c o t c |
Edit sequence |
C-c o t s |
Edit siblings |
C-c o B q |
Open query builder (interactive query building) |
C-c o B r |
Display query from root to point |
C-c o B p |
Display query that matches node text at point |
Aside from a handful of defaults in the C-c o t keymap, there are commands that build queries you can use as a baseline to create your own custom editors. My article on Editing and Searching with the new Query Builder goes into more detail on those.
Most commands that “Do What I Mean” require a context locus that serves as a limit for cursor editing. You rarely want to edit the whole buffer. That way you can limit your node editing to just the current statement or function, for example, without having to manually remove cursors after the fact.
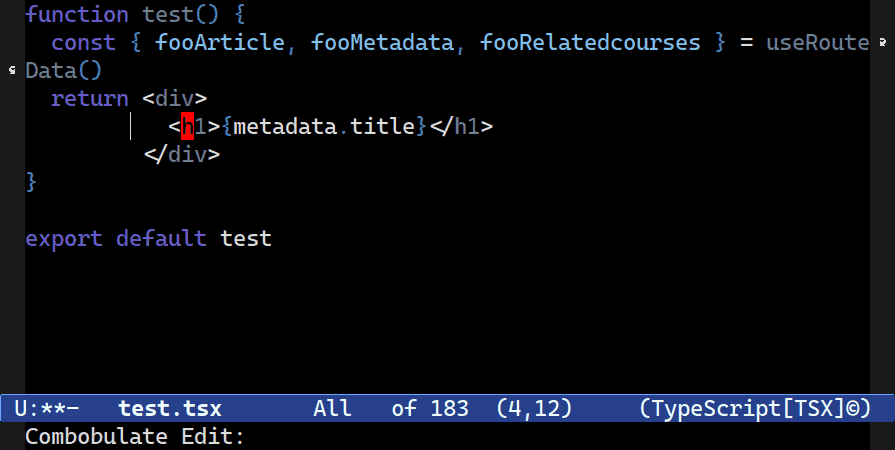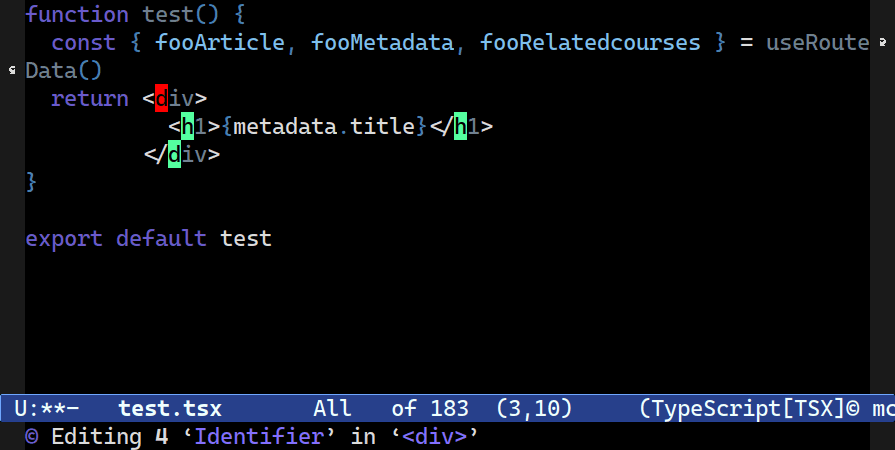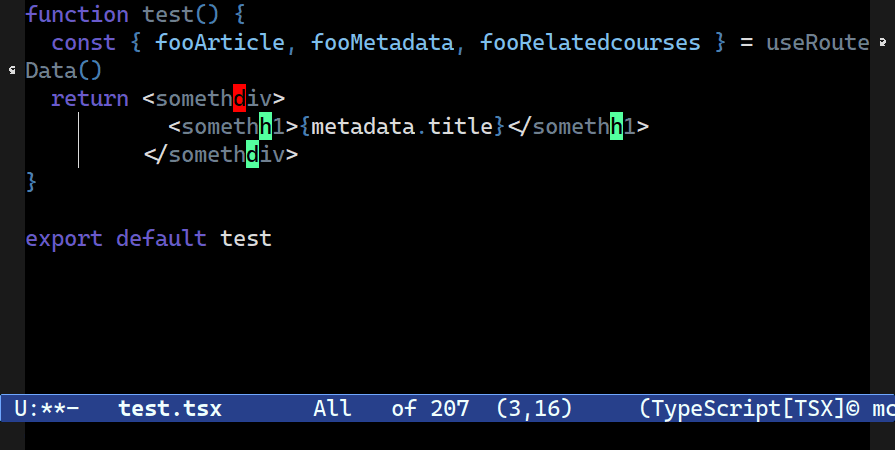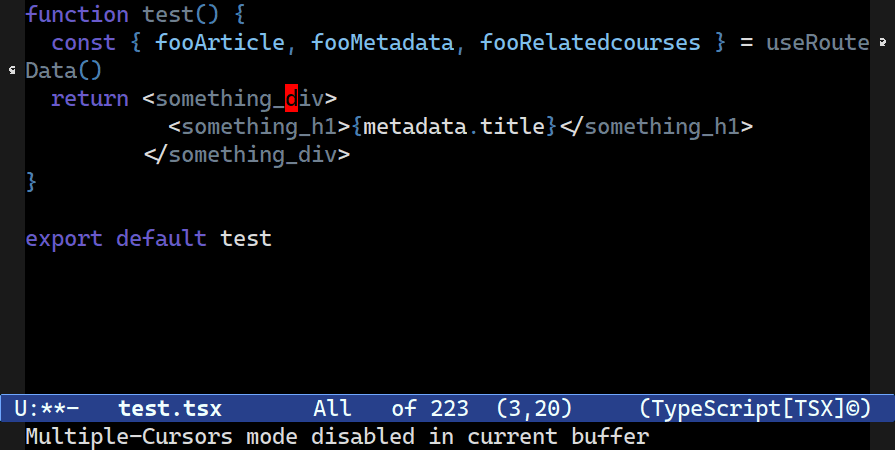
C-c o t t. You’re asked to confirm the locus (how far Combobulate should go look for nodes of the same type) to edit in one go, starting with just the element pair.Multiple Cursors
I like multiple cursors, and it’s a tool I use all the time, but it is an external, though optional, dependency in Combobulate, and while I’m OK with that, it’s also something I feel shouldn’t be required for basic bulk editing. I want people to at least be able to use Combobulate’s editing facilities without requiring multiple cursors.
Having said that, multiple cursors is well integrated into Combobulate. Every node has a start and an end, for example, so having the ability to insert a cursor at either end is especially useful.
| Modifier Arguments | Description |
| None | Place cursor at the start (default) |
C-u |
Place cursor at the end |
C-u C-u |
Mark the node |
You can control the placement of the cursors for any of the edit commands in the C-c o t key map by giving it a prefix key. By default cursors are placed at the start of a node; a single C-u argument changes that to the end.
One of the benefits of multiple cursors is that it supports non-contiguous regions, so each cursor can have its own region. To mark things instead, prefix with C-u C-u instead. At that point you can use C-x C-x to swap point and mark to move between the start and end of the node.
Combobulate’s Field Editor
Combobulate has an advanced snippet templating tool feature called envelopes (check out C-c o e ....) It has been around for a long time now (and more on that in another post!) and, like any good templating tool, it supports fields, but with an important difference: it uses the minibuffer prompt mechanism to query for input instead of expecting you to type into an overlay dyed and imbued with special properties in your buffer. Unlike the abandoned Tempo and Skeleton templating packages in Emacs, Combobulate updates the fields as you type in the minibuffer.
Because Combobulate already has a templating tool, it was a snap reusing the code as a cursor editing system that works a little bit like a trad templating tool crossed with C-x r t (M-x string-rectangle), another Emacs classic that uses the rectangle system in Emacs to prefix text. The string rectangle feature’s a little too basic on its own — it’s useful, for sure, but I figured I could make Combobulate’s editor a bit more ergonomic and flexible than simply reinventing such a basic mechanic.
A large part of the edits I make when I use multiple cursors are simple append/prepend operations to the existing text. Not always, but often. To facilitate that sort of editing, I needed a placeholder symbol in the minibuffer to represent each node’s text. Otherwise, I’d have no way of prepending and appending in the minibuffer: there is one minibuffer prompt, after all, but more than one node field to update, and each may have vastly different text.
Ergo, there must be a generic placeholder that represents each field’s node text. Thinking about it some more, I realized that this is really not all that different from the replace regexp’s capturing group feature found in, among other places, C-M-%.
So why not just use that? You gain a number of other ancillary benefits for “free” (well, it required more coding, but they’re benefits to you) when you start thinking about each node as its own capturing group.
| Feature | Description |
\0 |
Inserts the original text for each field |
\N |
Inserts the Nth field’s text |
\# |
Inserts the number of the field, starting from 0 |
\,FORM |
Evaluates the elisp form FORM. Capturing groups are valid inside the form. |
With a regular replace regexp, the \N notation represents the N’th match, with the number 0 being the whole match string. In Combobulate, \0 now represents the match string for each localized field you’re editing. So the default prompt value in Combobulate is \0 meaning: just insert the original text you started with.
All other numbers represent that particular node’s text. So \1 is the first node; \2 is the second, and so forth.
That means it’s possible to not only replace every match with the content of a particular field, but also combine them. Maybe you want to merge the second and third fields’ text?
Another regexp feature is the ability to insert the match number. By counting from the top-most field, you can insert the index of each field with \# as a practical and cheap way of enumerating things. It counts from 0.
C-M-% has a really cool – and quite hidden – feature: it can evaluate Lisp Forms inside Regular Expressions. I’ve written about it before; it’s such an underrated feature. I do not need it often, but when I do, it’s nice to know I can combine the power of elisp with regexp search and replace.
C-M-%. Here I’m uppercasing all the fields’ names using upcase and the \0 capturing group.In addition to all that, there are key bindings in the field editor minibuffer (you can also see the key bindings by tapping C-h in the prompt):
| Key Bindings | Description |
C-n |
Move to next field |
C-p |
Move to previous field |
C-v |
Toggle the current field on or off |
C-i |
Invert fields’ editable state |
C-h |
Show the help |
You can scroll through the fields with C-n/p. You’ll need these if you want a closer look at the matched fields. You’re free to just switch to the buffer and scroll also, of course!
Unlike multiple cursors, you can toggle the fields on or off. Do you want to bulk edit all the keys in a JSON object except one key? Now you can. Just move with C-n/p to the field in question and toggle it with C-v. C-i does much the same: it inverts the state of all fields.
The field editor’s not perfect, but then nor is multiple cursors.
A quick Comparison between the two
Multiple cursors is, to me, an indispensable tool, and I will continue to use it for things that warrant it.
The field editor is better for explicit, bulk edits where you do not require the flexibility or precision you get by having a point placed at every field.
It is not possible to gingerly delete some characters or operate on partial node text matches with the field editor. (Though I suppose you could try with the Lisp form evaluation.)
Simultaneously, it is not so easy to quickly prepend or append to the node text with MC. In fact, there is (to my knowledge) no way of declaring a ‘range’ to a cursor. Once it is created it is subject to the whims of the editing and movement you do in the buffer.
You can use the C-u C-u argument to mark the nodes, which does give you some control over the start and end, but explicitly inserting something at the start of the node and then the end is perhaps not possible at all, if the node is not something you can quickly find the ‘end of’ with either Combobulate’s movement commands or Emacs’.
MC does support some form of killing and yanking, but I find it awful and borderline unusable. If you want to merge or join nodes’ text together, you’re better off with a keyboard macro or the field editor.
The other major advantage of the field editor is that it ships with Combobulate. It is also relatively easy to add new, explicit, commands to do things in the future.
So. There are trade-offs to both approaches, but now you at least have a choice of what to use.
Let me know what you think.
Happy (bulk) editing!

