


Today, I want to discuss the difficulties of navigating code in a tree-sitter environment. For all the meticulous detail it adds, it also makes intuitive navigation hard. There are too many nodes going in all manner of directions and that’s, well… discombobulating.
How to efficiently move around your code using basic concepts such as moving up or down a node, or to the next or previous node, in a way that aligns with our human intuition, is not straightforward.
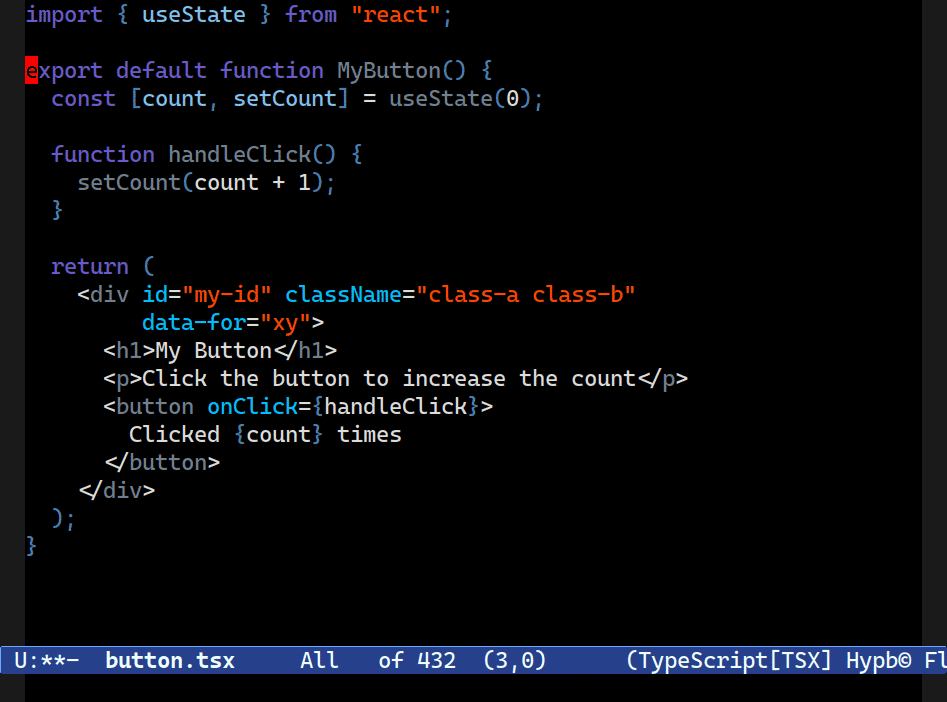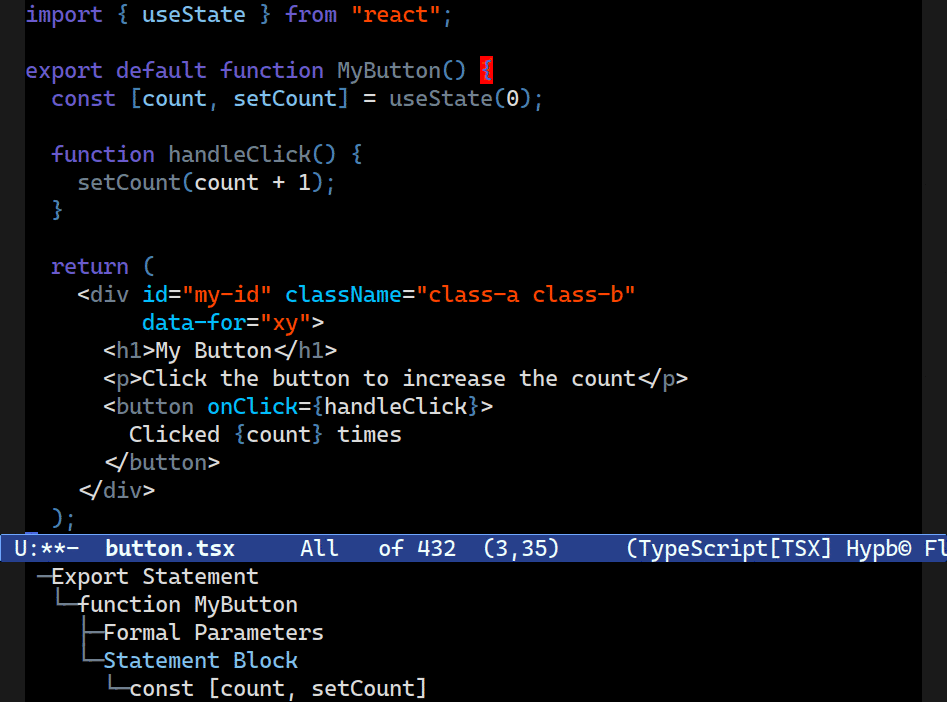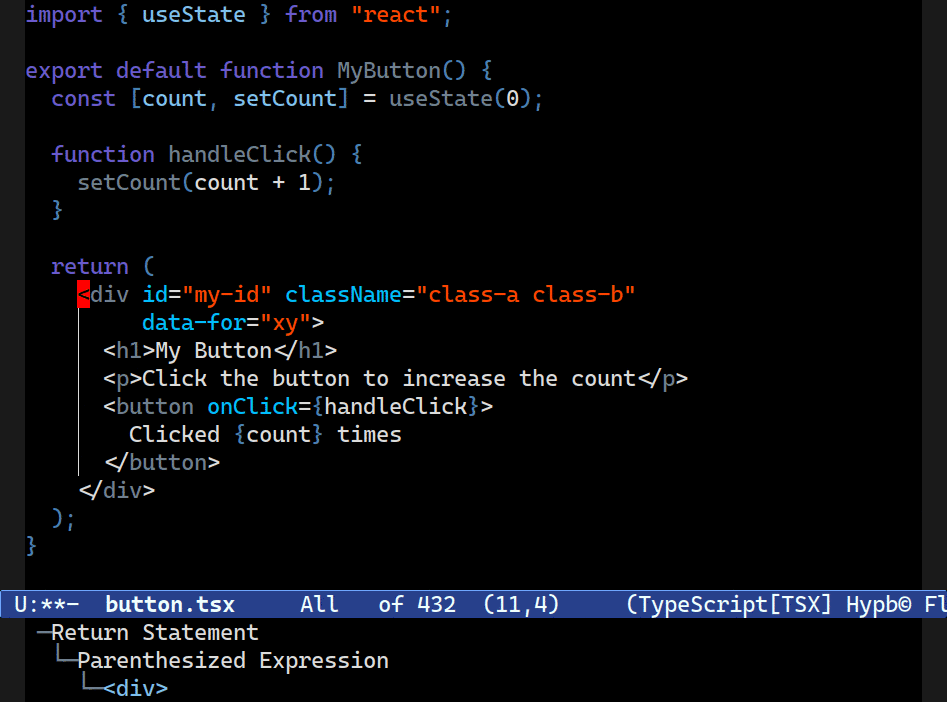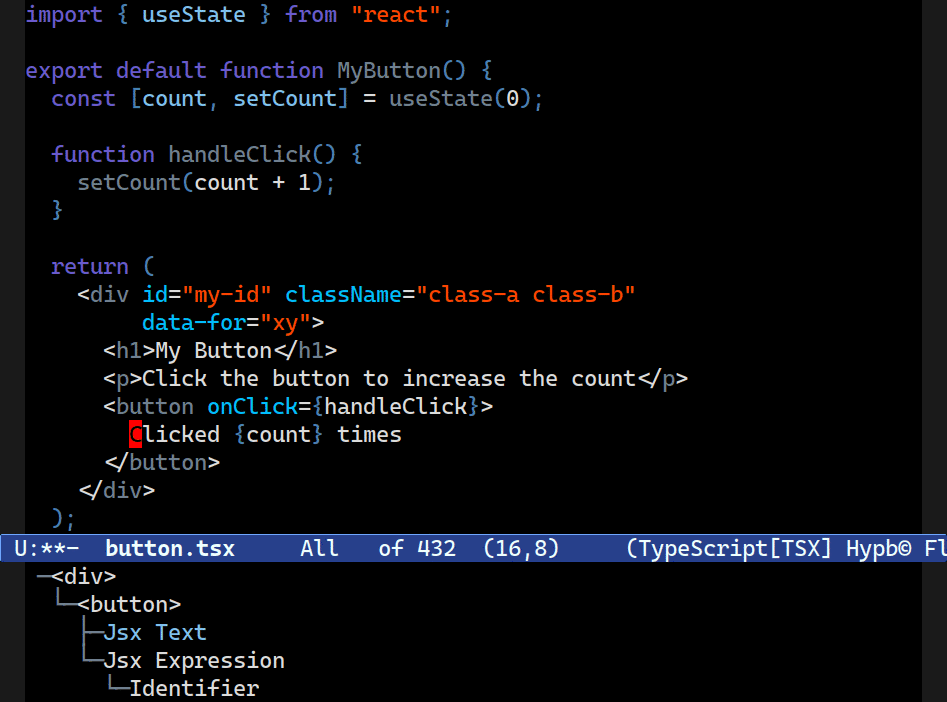
It really does sound simple, but I promise you it is not. Combobulate (Github), my package that adds structured editing and movement to Emacs, has long had a focus on improving navigation by taking advantage of the precise view of code that tree-sitter offers.
So I’d like to take a bit of time out to talk about the problems and solutions and, usefully, the benefits of solving the challenges.
Emacs is already full of navigational aids that help you get to where you need to go. To say nothing of the multitude of third-party packages that add novel and interesting ways of getting around also. What tree-sitter offers – and what Combobulate benefits from – is the precision that a Concrete Syntax Tree (“CST”) gives you. If you put in the work, it’ll make navigation (and editing; but this article is about movement) more precise, and make it available in a wider range of circumstances.
Lisp in Emacs has great movement and editing already, as you’d expect, but it’s also Emacs’s core programming language, and a syntactically simple language. So if you look a bit further afield, you’ll find other well-written modes like nxml-mode, Emacs’s XML mode, for another example of structured movement done well. It behaves as a seasoned Emacs user would reasonably expect.
The reason it’s great in nxml-mode is that it has a standards-conforming parser that truly understands what’s going on. Plus, XML is a straightforward enough language, so it was easy for its author to construct a cohesive narrative for how movement (and, by extension, editing) should work, much as it is in Lisp.
What, then, to make of Emacs’s expansive movement commands in modes that don’t have a parser, or some other method that can turn your garden-variety C, Javascript or Python code into a tree-like structure suitable for introspection?
How do you bring sensible navigation to complex languages? Programmers can easily tease out structure – it’s their job, after all, to find patterns in things – in code. But to make a machine do the thinking for us is harder.
Without a CST, you’re left with what ever you can claw your way to with regular expressions and gnarly imperative code. Your limitations are set by the inefficiencies of the tools at your disposal.
By contrast, with a CST, you have richness, depth, and far too much choice.
Combobulate’s Goals
When I set out to create Combobulate I wanted to capture all the things I liked about Paredit, a fancy structured editing tool for Lisp; Emacs’s general movement and editing commands; the breezy, structured movement you get in the likes of nxml-mode; and my own ideas on “Structured Editing” which, well, I’ll get to that in a future post!
I also wanted Combobulate to follow a set of rules, design philosophies, or what ever you want to call it. They’re really simple:
Enhancement. Combobulate should augment Emacs’s rich editing and movement suite and make them work in a wider range of circumstances, and have them behave in a manner that is consistent and familiar to someone with a little bit of practice.
Ease of use. Combobulate’s actually rather advanced now, but it should be simple to discover and experiment with its features. For every key that Combobulate binds to, there’s an equivalent transient UI (
C-c o o) that shows the user what they can do.Consistency. Language syntax aside, Combobulate should work consistently between languages, or as much as you can reasonably expect.
Extensibility. It should, with some experience and practice, be possible to add a new language to Combobulate without having to write endless custom code. All of Combobulate’s languages are procedurally specified.
There is no custom code, or magic hacks, for any of Combobulate’s languages, to make them work “in that one edge case”. There’s no “here’s a sneaky function to work around a quirk”, nor will there ever be. If it can’t be specified in Combobulate’s own little DSL, then it either won’t happen at all, or Combobulate must be extended in a pragmatic way so all languages can benefit from it.
Visibility. Having a full-blown CST at your fingertips can yield a mind-boggling array of choices. Combobulate will in most cases ask what you want to do when the context is ambiguous or if you deserve a closer look before it does something. Most commands that edit your code in some way will first preview the change in your buffer, live, so you can decide on the outcome.
These rules are important to me, as they help ensure that Combobulate behaves the same across all languages. The bit about not allowing an endless sea of language-specific elisp hatchet jobs is perhaps the most important. That does mean that really advanced features are much slower to appear in Combobulate than they would be if you were to, say, write the best ever structured movement and editing tool for one particular language.
Having said that, Combobulate does presently support a decent amount of different languages and formats: JSON, YAML, Python, Javascript+JSX, Typescript+TSX, CSS, and HTML. Adding new ones is not that much of a challenge; in fact, with the recent changes I’ve made and will discuss now, it’s easier than ever.
Getting Around Town
The thing at the top of my list to get right in Combobulate was consistent navigation across the board. That has turned out to be really hard to achieve. I’ve spent man-months tweaking, testing, writing and rewriting code to try and do that, before I finally settled on the system that is in use now. What started a year ago as a mini-DSL for one corner of Combobulate is now used everywhere.
You can’t just, like, move up, down, left or right in the tree and expect that to yield a useful movement experience. The CST is very granular, which is really good, but also kind of bad. An excess of choice can be worse than the absence of choice. Especially as it pertains to navigation. There are lots of packages out there that crudely expose the rudiments of tree-based navigation – all of it built in to tree-sitter – like go to parent; go to child; to go next or previous sibling. Call it up, down, left or right for a moment. None of this is hard to build and you could slap a primitive movement system together in no time at all, with barely a dozen lines of elisp.
But you don’t have just one choice, which would make tree movement fluid and simple, and this a rather boring article.
If you could hurl point, like a lead lawn dart, with great abandon, at any place in a tree-sitter-powered buffer, you’d hit a spot that would undoubtedly intersect five, ten, or fifteen nodes easily. Bullseye?
Which of those nodes do you choose for a ramshackle, scotch taped movement system?
You could opt to let the user choose the node they want to use. That would let someone traverse all different possible directions available around point. It’ll work, but it’s complex and fidgety; not fluid and simple.
Plus, I guarantee you that you’d wind up stuck in the unending number of cul-de-sacs and dead ends that these trees have. Even a simple snippet of code can have hundreds of nodes with a mind-boggling number of leaf nodes. Most concrete syntax trees resemble a shrub more than an actual tree.
Anyway. I built such a movement tool back in the day: moving around like that is comically awkward and beyond useless in all but the most basic of grammars. Few humans can inuit where they are and much less where they need to go. Here is the tree-sitter playground. Heavy a small function into it and tell me if you think that tree is easy for a human to navigate without an actual map next to you. Nuh-uh. No, thank you.
Which then leads me to the underlying point behind it all. One of the hardest things to build is to come up with a way of picking the nodes you, the human, want to move to given the location of point and your intent. Building the code that can determine the correct sibling node to move to is surely one of the hardest things I’ve built in Combobulate. If you’d told me that when I set out to write Combobulate – and I say that as someone who has long had an interest in language parsing and how to build tooling around it – I would’ve laughed out loud.
That’s really what I want to talk about: why it’s hard; how I came up with what I think is a good solution; and how users of Combobulate get to benefit from this cohesive, new system.
For all the munificence of a concrete syntax tree, it does complicate matters greatly due to the sheer resolution of the tree. We’ve all wanted this sort of flexibility and now that it’s here, it’s just a mountain of work. Be careful what you wish for, eh?
Step by Step
But let’s get back to general navigation and how a naive Mickey would go about building it from scratch. Start with sibling navigation.
def foo(arg_a, arg_b):
-!-if a + b > 0:
do_something(a)
a, b = do_something_else(
a,
b,
)
return a + bLet’s say point, -!-, is at the beginning of if. Sibling navigation – in Combobulate it’s bound to C-M-n and C-M-p – should take you between each of the three statements seamlessly. You cannot go to the previous sibling from if, as you’re already at the beginning. If you try to go to the next sibling, your point is placed at the beginning of a, b = do_something_else( ... ); again, and it’s placed at the start of return.
Likewise with function parameters for foo. With point at arg_a, it should take you to arg_b when you type C-M-n, and back again with C-M-p.
It’s a simple ask. Ask any programmer – even someone who has never laid eyes on Python – where point should move to if you want to go to the next “line of code” and they’d intuitively point out the logical place to go. Sure, you can end up with ambiguities where it’s not so clear, but, I think, in a lot of cases, it is.
The trouble is actually programming it.
Combobulate started its life with a naive view of how to do these things, and it was only when Emacs 29 and official tree-sitter support came out that I put in a lot of time to making it more robust. Before that Combobulate – and, well, it still is to this day – served more as vehicle for my hobby research into building generalized structured editing and movement.
To make sibling navigation work, and to make it more robust – Combobulate is still not perfect, I admit – you must throw away any notion of a “heuristic” that will magically solve this problem. I tried; trust me, I tried.
The simplest and most obvious question (and answer) is this: surely tree-sitter can tell you its siblings? Indeed it can! treesit-node-<next/prev>-sibling do just that. They take a node and return its immediate sibling, if there is one.
All done, right? Not so. Consider that you may have more than one node to get its siblings from.
Take a look at this line of code:
# ... rest of code ...
-!-a, b = do_something_else(a, b)
# ... rest of code ...At point -!- there are four nodes that start at the place point is at. Crack open IELM, Emacs’s builtin repl and check it yourself:
ELISP> (combobulate-all-nodes-at-point)
(#<treesit-node identifier in 63-64>
#<treesit-node pattern_list in 63-67>
#<treesit-node assignment in 63-114>
#<treesit-node expression_statement in 63-114>)There are four nodes that start at point. The numeric range is the extent they occupy in the buffer. identifier at 63-64 is a one character long identifier with the node text a. Makes sense when you consider the position of point and the line of code ahead of it.
The other three are more specialized node types: pattern_list is a, b indicating a basic form of destructured binding in Python when it’s on the left-hand side of an assignment; the assignment is obvious enough in the context of the previous node; and expression_statement is the whole shebang.
So the most obvious and naive attempt is to cycle through the nodes and picking the first node that has a sibling.
Unfortunately that’s also the first thing you’re likely to try. But will it work? Probably, I guess. Sometimes.
But consider a brace of nodes, each with one or more siblings.
Let’s figure out how many siblings our clutch of nodes have:
ELISP> (mapc (lambda (n)
(princ (format "Siblings of %s:\n\tNext: %s\n\tPrev: %s\n"
n
(combobulate-node-next-sibling n)
(combobulate-node-prev-sibling n))))
(combobulate-all-nodes-at-point))
Siblings of #<treesit-node identifier in 63-64>:
Next: #<treesit-node identifier in 66-67>
Prev: nil
Siblings of #<treesit-node pattern_list in 63-67>:
Next: #<treesit-node call in 70-114>
Prev: nil
Siblings of #<treesit-node assignment in 63-114>:
Next: nil
Prev: nil
Siblings of #<treesit-node expression_statement in 63-114>:
Next: #<treesit-node return_statement in 119-131>
Prev: #<treesit-node if_statement in 21-58>Ambiguities abound. So our original heuristic needs tweaking. That one, pedestrian line of code I showed you before has four nodes that start at point alone. And three out of four them have siblings!
The smallest node, identifier, has a sibling of its own: the identifier with the node text b.
So if you want sibling navigation to go into the pattern list, you’d have made the right choice if you picked the first node starting from the smallest.
In this case, I’d argue that is not what a programmer would expect.
They’d be walking along, merrily, only to get pulled into a pattern list with no real recourse to get back out again: navigating to the previous or next sibling according to our rules would limit us to just the a and b identifiers. Why? Because we always pick the smallest node, so at a we’d only ever pick its sibling b; and at b, its only sibling is a. We’re trapped.
The only way out is to navigate out via several parent nodes (three, in actual fact) to get back to the expression statement we were cruising along earlier.
One tantalizing observation is that, if you look at the sibling nodes available to us, the largest node – the expression statement – point to the other two nodes (if_statement and return_statement) we would logically consider to be siblings.
So why not just use the largest node? Let’s try it. combobulate-all-nodes-at-point returns all nodes that start at point ordered from smallest (nearest) to largest.
ELISP> (thread-first (combobulate-all-nodes-at-point)
(last)
(car))
#<treesit-node expression_statement in 63-114>(Here I’m using ``thread-first`` to cut down on repetition, but it’s not required at all. The output of ``combobulate-all-nodes-at-point`` in ``thread-first`` is passed to the subsequent form, ``last``, and its output to the one after that, and so on.)
Okay. Great. Given all the nodes at point; get the last cons cell; then get its first element. That happens to be the expression statement, which is the one we want.
Let’s get its previous sibling:
ELISP> (thread-first (combobulate-all-nodes-at-point)
(last)
(car)
(combobulate-node-prev-sibling))
#<treesit-node if_statement in 21-58>Okay, so our heuristic pans out. Given the largest node at point, its siblings yield the right nodes we want to allow us to move “between lines of code” as most human developers would interpret that phrase.
Pop over to the buffer and move point (IELM does not like moving point programmatically, which is really very annoying) to the beginning of the if_statement. On my computer that’s point position 21 (try it with M-g c.)
We’ve tested it works one way. Now let’s head back. From the if_statement let’s move to its next sibling, or the one we just came from, by first applying our heuristic to find ourselves:
ELISP> (thread-first (combobulate-all-nodes-at-point)
(last)
(car))
#<treesit-node block in 21-131>Hmm. Hold on a moment. That’s not our if statement! We need the if statement to pick its sibling. Indeed, block does not have siblings at all:
ELISP> (combobulate-node-next-sibling *)
nilSo. What went wrong? Most programming languages collect groups of nodes like the ones we think of as “lines of code” into block nodes. Here’s it’s literally called block. In Javascript it’s statement_block or some other name like that. Collections of nodes are held in a ‘meta-node’ that in this case encompasses all the nodes in the def block.
You can test it out by asking for the children of block:
ELISP> (combobulate-node-children **)
(#<treesit-node if_statement in 21-58>
#<treesit-node expression_statement in 63-114>
#<treesit-node return_statement in 119-131>)So, the heuristic of using the largest node works just fine… right up until you decide to use it on the first line of code in a block. The block node starts at the exact same point as our putative if_statement node, only it’s much larger:
ELISP> (combobulate-all-nodes-at-point)
(#<treesit-node if_statement in 20-57>
#<treesit-node block in 20-132>)So our heuristic to use the largest won’t work either. Now you’d have to extend the heuristic to handle exceptions, and special rules, and sneaky hacks, and…, oh my, it’s all getting a bit complicated. And before long you’ll run into other awkward scenarios like this piece of HTML (or JSX, as it’s the same node configuration):
<foo>
-!-<bar/>
<baz>
foo
</baz>
</foo>Where the previous sibling to <bar/> is… <foo>! Because in HTML the tree structure is (element (start_tag) ... (end_tag)). Which in our particular case would look a bit like this pseudo-tree:
(foo_element
(start_foo_tag)
-!-(bar_self_closing_element ...)
(baz_element ...)
(end_foo_tag))HTML tags have an element that encompasses the entire cluster, which is sensible, but it also needs two sub-nodes to accurately represent the beginning and end of an element: one at the start, and another at the end. They have to go somewhere, and the only logical and correct place is to be children of element: being the first and last, respectively. And now you’ve got unwanted ‘step’ siblings. Now you’re going to have to deal with this in your sibling navigation code, and that’s yet more exceptions to build into your heuristic.
So, yeah, it’s complex. Heuristics don’t work. And if they do, they’re liable to break if the language grammar changes in your favorite tree-sitter plugin (that does happen.) So then you get it working again – yay – and add support for a new language, and that language snaps your carefully-made assumptions in two.
You can’t rely on heuristics. You can’t be a lazy developer and think you can code your way out of this with The One Algorithm like I thought you could. Not if you don’t want your heuristic to fail in strange and wonderful ways, like not working on the first statement in block.
It took me a lot of rewriting and retries before I declared the approach a total failure. It took me even longer to zoom in on a system that lets me solve the “sibling problem” but also the other, equally awkward, problem of picking the right child node to choose for when you want to go “into” a line of code.
Moving between siblings is great, but picking the right child node to move into is just as difficult!
Up and Down
This problem has plagued Combobulate for a while, and until very recently, it did not use the specification language I invented for sibling navigation in other parts of Combobulate. That resulted in me having to write some rather complex parent-child navigation code that, actually, you know what, worked quite well in most of instances.
Except it broke in one of the most awkward places: moving down into HTML/JSX elements. When Combobulate encountered a tag it’d go into its attributes with C-M-d whereas it should, rather more naturally, take you into the element to its first child (be it text or another tag). Now it does the right thing because I can distinguish between being at a node or just inside it.
Before I made this change the child navigation code would go into the attribute instead. Useful, generally, but not from where point was. If it did it inside the div element itself it’d make perfect sense, but not right outside it. Thankfully, with the new procedure system for parent-child navigation this issue is now resolved.
To make this work I use a (relatively) simple DSL that looks a bit like this:
(:activation-nodes
((:nodes ("jsx_fragment" "jsx_element" "jsx_expression")
;; use `at' because it ensures that point is at the jsx
;; element we wish to enter.
:position at))
:selector
(:choose node :match-children t))The activation nodes – you can have many of them, each with their own position rule and nodes – instructs Combobulate to look for the node types you see above. Here the point must be ‘at’ the node start of a fragment, element or expression in JSX. This rule will only trigger if that condition is met.
All of the fields that take node types do so using a simple rule expansion system that itself has a little mini language captured in combobulate-procedure-expand-rules.
Node type production rules are generated by the tree-sitter grammar compiler automatically. Combobulate then has a script to build a combobulate-rules.el file containing all of them in an easier-to-parse format.
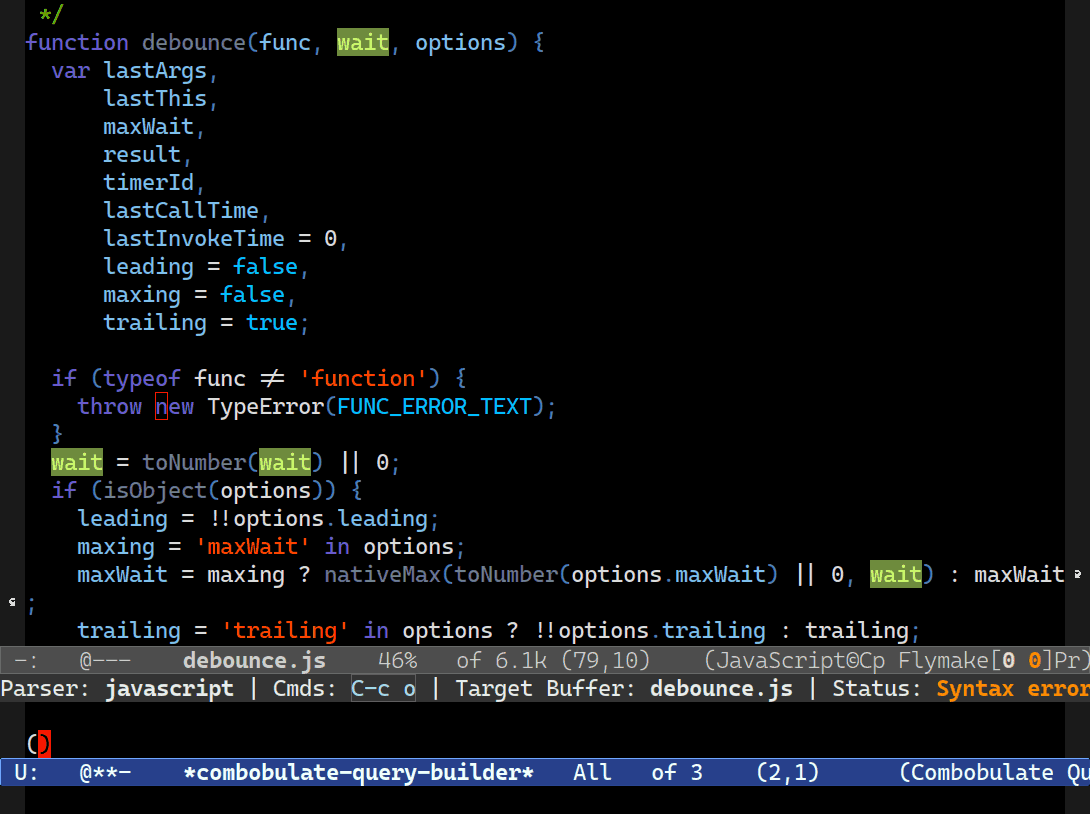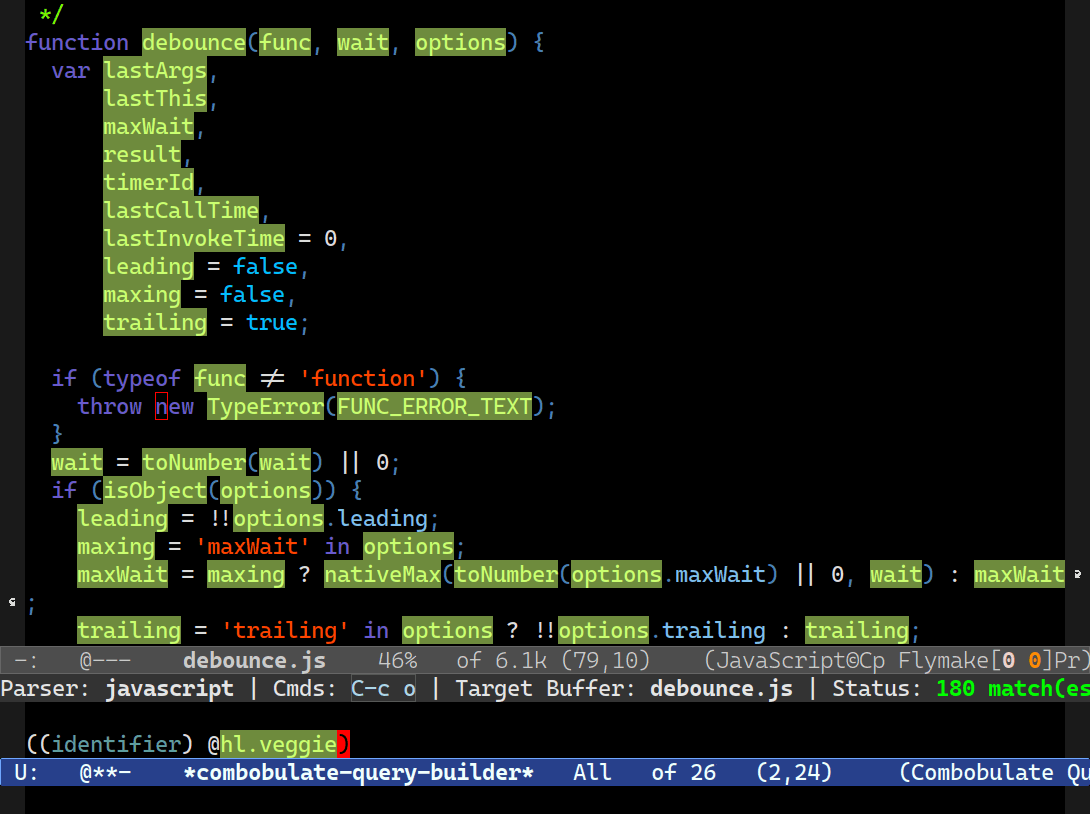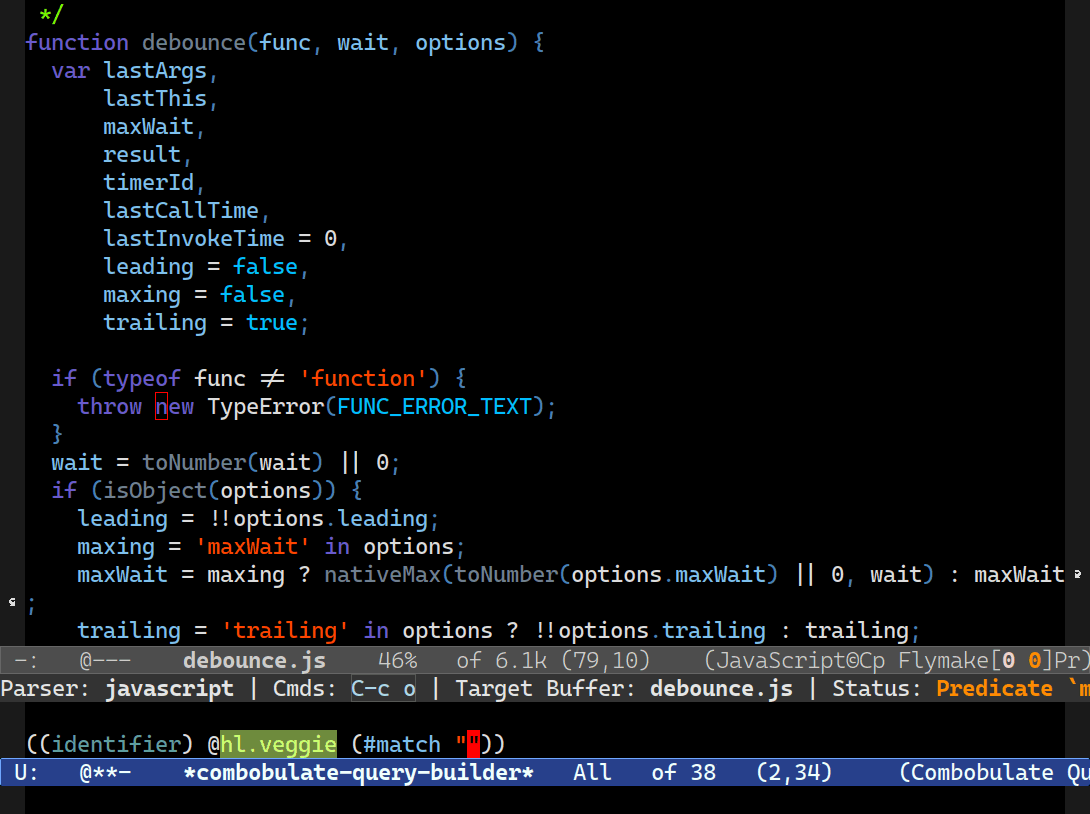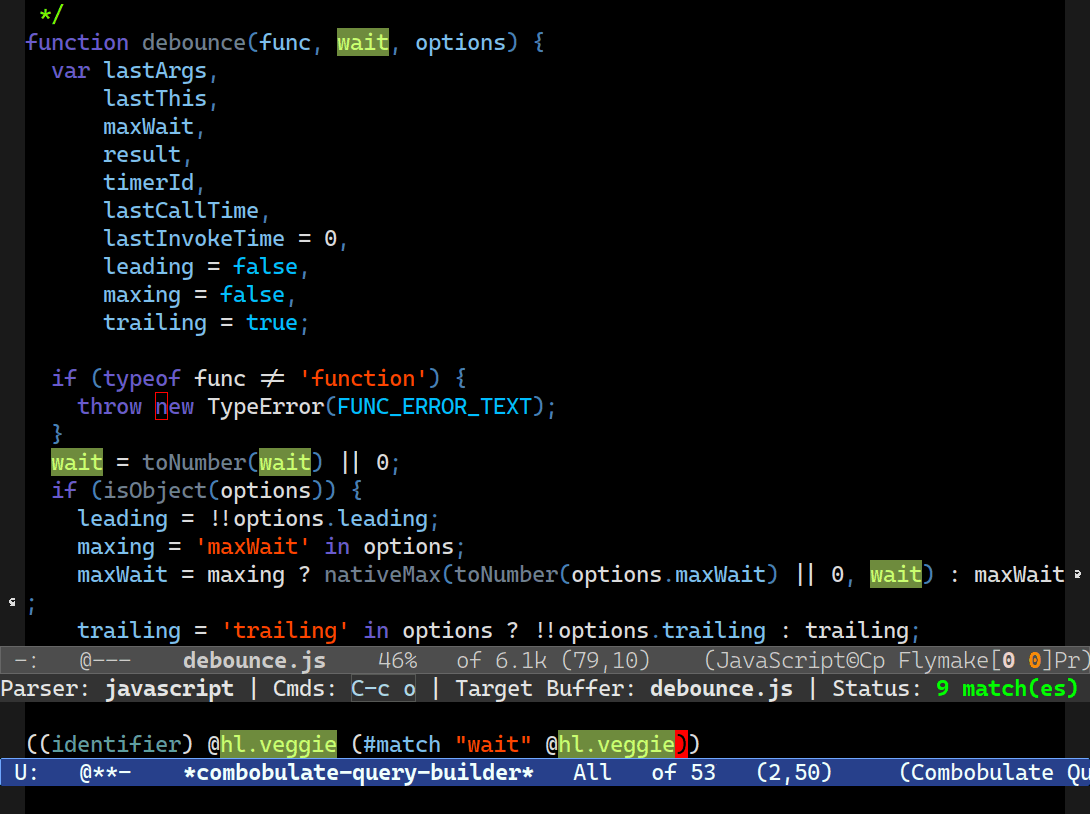
That’s how Combobulate’s interactive query builder works. It uses the rules file to provide code completion for node types and fields, and it knows which node types can go inside other nodes.
Going back to Python for a moment, we can ask it to list all the node types that belong to the production rule if_statement, but only the ones that are valid inside the condition field of an if_statement:
ELISP> (combobulate-procedure-expand-rules '((rule "if_statement" :condition)))
("as_pattern" "comparison_operator" "false" "generator_expression" "list_comprehension"
"float" "unary_operator" "await" "set" "dictionary_comprehension" "attribute" "integer"
"binary_operator" "parenthesized_expression" "tuple" "ellipsis" "concatenated_string"
"true" "none" "string" "set_comprehension" "identifier" "list" "call" "dictionary"
"list_splat" "subscript" "conditional_expression" "boolean_operator" "lambda"
"named_expression" "not_operator")You can then further refine your scope with exclusions, regexp matching, and more.
Combobulate’s had support for interrogating a language’s production rules for a long time, but they were cumbersome to use with the old procedure system, so now it’s built in.
The :selector, if there is one, tells Combobulate what to do with the matching activation node. In the example above it’ll choose the activated node and from that node it’ll get its children. But if you had a :has-parent or :has-ancestor requirement, you could optionally ask the selector use one of those to match from instead of the activation node.
The selector can optionally match children, siblings, or use a tree-sitter (or Combobulate) query to winnow down the matches you want. Adding more selectors or activation criteria is easy, if there is ever a requirement.
The advantage over a heuristic is manifold, but of course you have to teach Combobulate how to move around. I’m experimenting with generic fallback rules so something always happens if you’re trying to navigate in places Combobulate lacks rules, but I’m not going to release that code unless I feel it adds more value than it takes away by being unintuitive. Combobulate should be predictable and dependable, first and foremost. Luckily, most rules can be generalized across a swathe of node types, hence the need for picking node types by production rule instead of having to list them all out by hand.
Not Quite Sibling Navigation
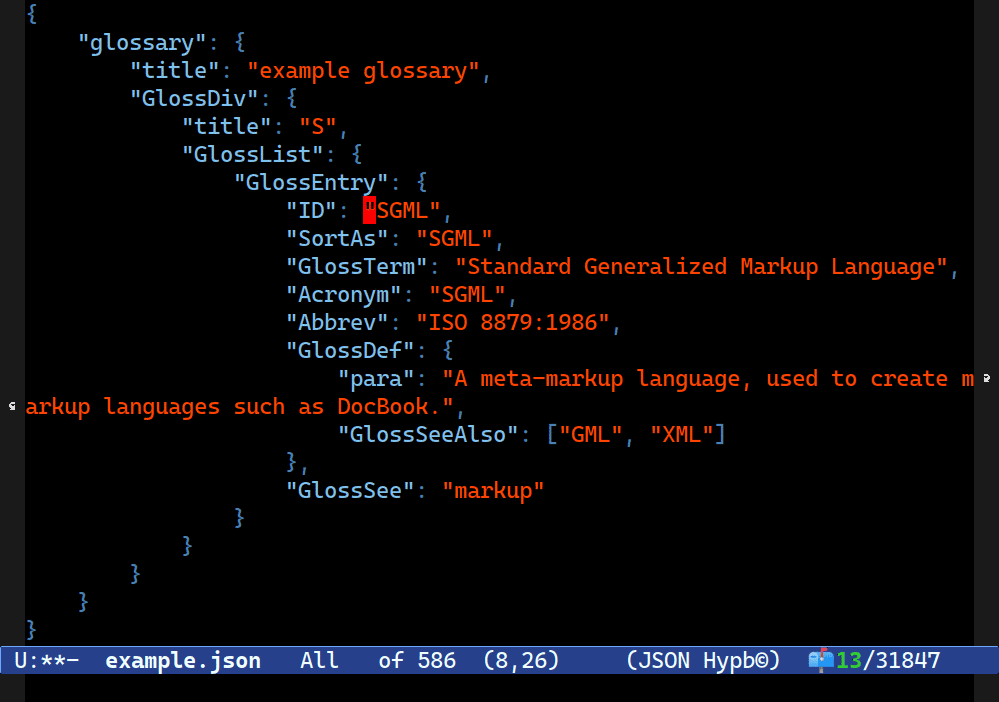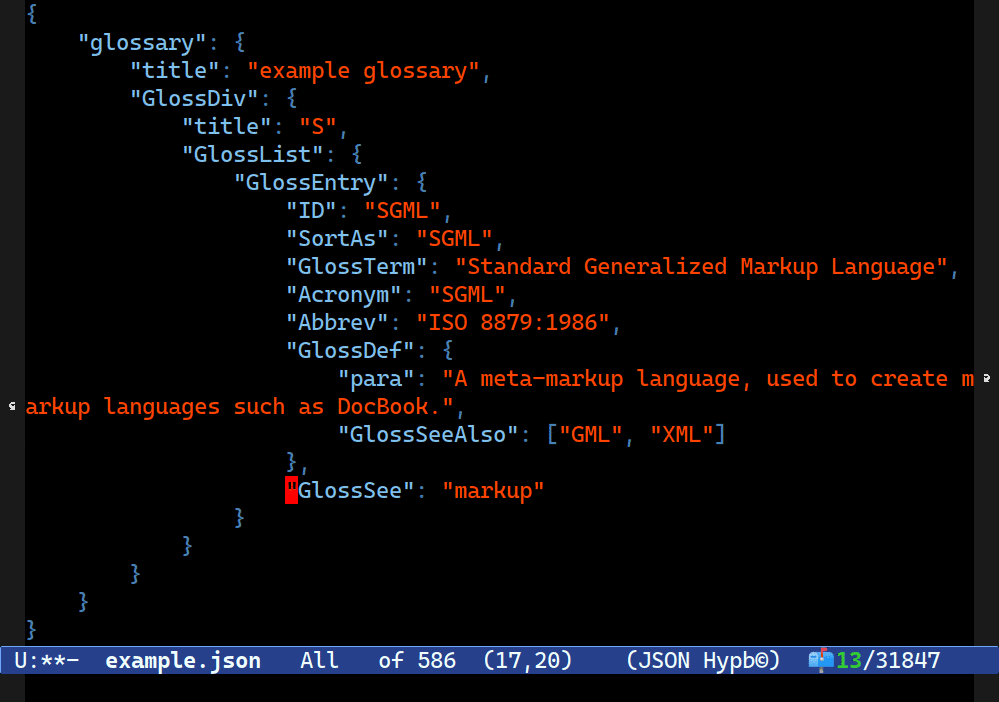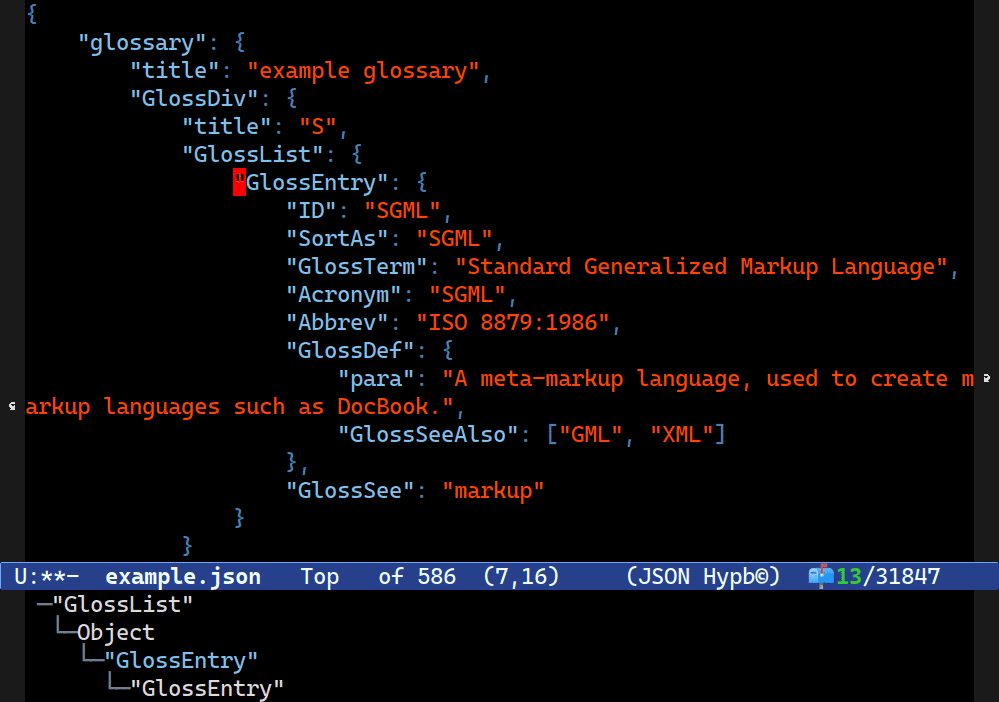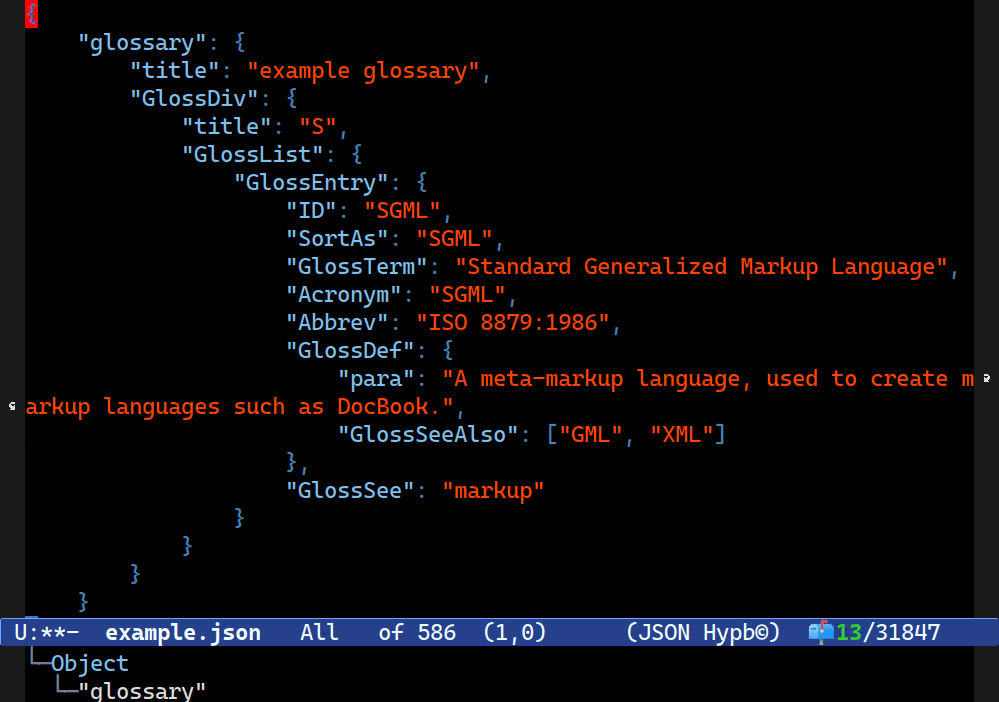
For instance, this is Combobulate’s sibling navigation in action (so you’d move between them with C-M-n and C-M-p), but it’s moving along the values in JSON as opposed to the keys.
Doing this with a heuristic is perhaps not impossible but much harder. None of our rules we tried above would work here. To start with, they are not siblings: more like kissing cousins. The structure of an object in JSON looks a bit like this:
(object
(pair key: KEY-NODE value: VALUE-NODE)
(pair key: KEY-NODE value: VALUE-NODE)
...)So to move along the value as though they were siblings, Combobulate has to ensure point is at a value node, inside a pair, and then find the sibling of that pair, and go back into it to get its value field node.
The rule looks like this.
(:activation-nodes
((:nodes ((rule "pair"))
:has-fields "value"
:has-ancestor ((irule "pair"))))
:selector (:choose parent
:match-query
(:query (object (pair (_) (_) @match)+)
:engine combobulate)))You can still walk along the keys in the object, too, of course, which is why the idea of a wondrous heuristic that can do it all is doomed to begin with. You’d need many of them, and you’d have to pick when to use the right one! And then before you know it, you’ll have arrived at where I am now with the procedure system.
The procedure system’s been in use for quite a while in Combobulate, but now it’s rewritten and so is most of Combobulate’s navigation system.
It has greatly improved not only sibling navigation, but also parent-child navigation and made it much easier to specify things. It’s still not perfect; there are blind spots where I haven’t cottoned on to sibling navigation being useful, or errors where I’m too sloppy with the rules. But those things are fixable! Easy-peasy.
As an added bonus, the system that finds and matches procedures is now used to improve the splicing functionality (like M-<up> in Paredit), one of Combobulate’s “experimental” features that only worked in a few isolated instances. Now it’s ridiculously capable, but that’s for another blog post.
Let me know what you think of the new improved movement system.

